Engineering technoVIT: My experiences as a college fest organizer
Table of Contents
- Little did I know
- Beginnings
- Taking Charge
- The First Meeting
- Progressing Ahead
- Exams and Launch
- Mid-exam Bug Hunt
- The Vibrance Story, Fixing Past Mistakes
- Exams are over, Deadlines it is
- The CMS Story
- The Pricing, doomed; Engineering it is
- The Missing Designs: Emergency
- The Collapse Era, The Tech Drama: Teaser Video
- The Diwali Outage: AWS, the Unexpected Guest and More Drama
- The Mini Public Launch: Failed
Little did I know
This was not my first time working for the college for a fest, I did work for my annual college cultural fest Vibrance as a volunteer which happened in March 2025. Just as the last time, this time as well, I was called to work but for the tech fest technoVIT in September of 2025. This time, however, things were different. I was given the responsibility of managing the entire tech team for the fest, and some part of the overall tech in the fest as well.

This is a small part of our technoVIT website committee whoever came for the Valedictory ceremony, including me (third from left), and my other teammates as well as university administration, from the left to right: Dr. Sankar Ganesh S, Verappan S M, Me, Dr. Jayasudha S, Dr. Joseph Daniel, Dr. Sathiya Narayanan S, Dr. Ganesh N, Abhinavanagarajan A, Shriansh Tripathi, Rakshana V and Katyayni Aarya.
Beginnings
It was just another day in college when I received a message to apply as a volunteer for technoVIT. I joined the team as a volunteer, and attended the first meet. There, I met the entire team and was briefed about the fest. I was excited to be a part of it, and was looking forward to working with the team. This website team was entirely created by Verappan bhaiya, who was my senior in college and was in his final year. He had been the organizer for college events for a long time and had a lot of experience in this.
Work started precisely on the 17th of September 2025, right after the first meeting was held. By that time, we also got a Figma design file which was continuiously being updated by the design team. We decided a color palette for the website based on the design file, and started working on the website. We mainly decided to follow kind of what graVITas website looked like, organized by VIT Vellore, the main campus of VIT.
The first task was to set up a repository for the fest website. I volunteered to do that and created a GitHub repository for the same. All of us collectively decided to use Next.js for the website, as everyone had a good idea on how to use it and it had a lot of features that we could use.
The first thing we developed was a countdown timer for the fest. Initially, I didn't have much time to work on it, so others took the lead and developed the initial version of the timer. The first job I was given was to deploy the website. I used Vercel for the deployment as it directly integrates with GitHub and is natively supported by Next.js.

This is how the first version of the website looked like. It was a simple one-page website with a countdown timer and hyperlinks to the social media handles of technoVIT. This was a mock version of a CRT monitor, which would later be the home page to technoVIT 2025 for sometime.
The website had a few build issues, so before deploying the website, I fixed the build issues. To prevent the breaking of the production (master branch), I created a basic CI/CD pipeline for the website which would build the website on every push and pull request to the main branch.
Something was slowly building up, which I never expected. It would later turn out to be a culprit for a major surprise collapse. 👀
I also set myself and Verappan bhaiya as the CODEOWNERS so we must approve changes and merge to the master branch. I set up branch protection rules as well to ensure that no one could push directly to the main branch, and everyone had to create a pull request for any changes.
However, in the evening of 20th September, Verappan bhaiya asked me to take over as the organizer for the website committee mentioning he was just there to guide us and help us in case of any issues, and he was the major point of contact between us and the college authorities. I accepted the responsibility and took over as the organizer for the website committee. To the other members, he asked them to take on other roles as well, that were Coordinators and Volunteers.
Taking Charge
For the first few days after role assignments, we took inspirations from a few different places. Design team was working on the designs, and we were creating the website based on the pages which were finished. We created a few components which would be used across the website, like the Navbar, Footer, Button, etc. We also created basic templates for the pages, like the Home page, Events page, Sponsors page, etc.
During this time, I also had to make a gradual shift from being a developer to being an organizer. I had to manage the team, assign tasks, and ensure that everyone was on the same page. I had to meet different people, including college authorities, Faculty Organizers and being in touch with the Students Welfare Committee of our college which was the main body organizing the fest.
For the first few days, the development was a little slow. We had to wait for the designs to be finalized, and we ourselves were looking at some cool designs to take inspirations from, we chose some of them to be a part of the website.
The First Meeting
I was called to a meeting with the Student Welfare Committee on 28th September, where they talked about how they plan the fest to go on and what roles and responsiblities we had as a committee. They also talked about the new hierarchy that was being introduced this year, with the addition of Faculty Organizers who would be the point of contact between the students and the college authorities.
Earlier, the fest was heavily decentralized and was being managed by different schools in the college, like School of Computer Science and Engineering, School of Electronics and Electric Engineering, School of Advanced Sciences, School of Mechanical Engineering, etc. Each school had its own team and was responsible for organizing events related to their field.
This year, however, the fest was being centralized and was being managed by the Student Welfare Committee itself, with the help of Faculty Organizers and Student Organizers handling their own committees. This was a big change, and I would say it made the fest more organized and streamlined, cutting down a lot of unnecessary delays and miscommunications.
In the meeting, they also had a bit of talks talking about motivating us to be more responsible and take ownership of our roles. They emphasized on the importance of teamwork and how we all had to work together to make the fest a success. I met a lot of new people in this meeting, including the last year Overall Organizer of the college cultural fest Vibrance, Monish bhaiya, who was now another Student Organizer alongside me for technoVIT. This felt great as I had worked with him in Vibrance as well in the website team, where I was a volunteer.
Progressing Ahead
By the beginning of October, I already had started to put issues in the GitHub repository holding the website code, and assigning them to different members of the team. By this time, I also had contacted our committee Faculty Organizer Dr. Prasad M and had a meeting with him regarding the progress of the website and the fest in general. He was very supportive and gave me a bit of guidance on how to continue and what to do next and a little bit on the timelines as well.
To get the website on the college's official domain, Verappan bhaiya helped a lot as he was basically the direct contact between me and the university Centre for Technical Support (CTS) team.
This was the first time I had a hurdle. The domain used last year for technoVIT'24 was lost, and we had to plan for a new domain fairly quick as we had just about a month left for the fest to begin. After discussing with Verappan bhaiya, Prasad sir and Sankar sir (Assistant Director Students' Welfare), we decided to go with the domain technovit.vit.ac.in.
The CTS was responsible for managing the college's official website and domains. With their help, we were able to get the website on the official domain for technoVIT'25. Verappan bhaiya coordinated with the CTS team and I sent him the Vercel deployment details so they could point the domain to the Vercel deployment.
Exams and Launch
The website was then live on the official domain on 3rd October 2025, and this was cool, until we found out that we had to show a sample of the website to the college authorities on 6th October 2025.
This was a big challenge as first of all, all we had were broken parts of the website, not in a single page, and second, all of the website team including me had our second mid semester examinations going on. This meant none of us were free to work on the website to develop the homepage. Verappan bhaiya took the lead here and worked on the homepage with Aruna bhaiya.
To not disturb the main repository, he created a separate repository where he put the website code that they needed quickly for the demo. They created a really good website in just a day or two, with the pages Home, Team,and About. This was just temporary, and we planned to create the full website after the exams.
So I put their code in the main repository and kept there as a temporary homepage until we could develop the full website. The demo went really well, and the college authorities were happy with the progress we had made. I had my Cloud Architecture Design exam the next day which was open book as well, so I had to do this and fix a few build issues and deploy the website on a separate sample domain. I did this by evening after I wrote my examination notes and we were all set for the demo.
At this point, we decided to make the code public as well, not to show it to public as the main purpose, but to allow Vercel to build the website on any codeowner's push as the code was deployed from my Vercel account and Vercel build only worked for my commits. This was a major step; this later also gave the code more visiblity as well.

This was the demo website we showed to them and it worked really well. The college authorities were really happy with this, but there was an issue.
They liked this way too much; so much that they wanted this to be the design theme for the final website as well!
This was a big challenge for us as we had to now create the entire website in this theme, which was not what we had planned initially. We told this to the design team, and had a little talk with them regarding this.
Mid-exam Bug Hunt
On 7th October 2025 we had a rapid-fire bug-fixing session. I had my exams going on, they were to end on 11th October. Verappan bhaiya pushed a quick build to the repo, I resolved a few build errors, checked responsiveness, and removed a stray arrow. I reviewed all the commits, manually deployed the changes, fixed the icon and build errors, moved the logos/hamburger to improve layout, and made the site responsive before pushing to the main site.
Verappan bhaiya then requested a few final cosmetic tweaks (swap the VIT and technoVIT logos and remove “VIT Chennai” from the central logo), and arranged a post-exam offline planning meeting plus lab/SWC Wi-Fi access so the team could finish the remaining design and deployment work.
On 8th October, Verappan bhaiya reported a video playback issue on the homepage. The teaser video wasn't playing after the first visit due to a local-storage flag suppressing repeat playback. I updated the logic to ensure the teaser plays once per visit and not vanish forever. The large video triggered a harmless 206 partial-content response, but playback worked normally after the fix. With that resolved, the page was ready for the Vice President's review the next day.
Keep this teaser video in your mind, as this will be a major culprit of surprise collapse later on. 👀
The Vibrance Story, Fixing Past Mistakes
Around the same time, we aligned on how event data would eventually flow into the site. Prasad sir asked whether we had begun pushing events, but since the final list wasn't approved yet, the faculty advised us to hold off.
In Vibrance'25, event data came through a fixed API provided by the university, which meant every change had to go through a formal request process and deployment cycle which took a lot of time!
Now, the Vibrance story, mainly the API and the responses. The main issue with Vibrance'25 was that the event data had a culprit, the posters. The API was hosted in the VIT servers, so there was no CDN (Content Delivery Network) to ease off the servers for the images. Second of all, to add to all of the burden, the images were Base64 encoded in the JSON responses, which made the API response size huge, and made the loading of the events page really slow.
The pages took a lot of time to load, and hogged user memory to more than 4GB because the browser was storing all the Base64 encoded images in memory. This made the user experience really bad, and we received a lot of complaints regarding this. Last time, to fix this, I created a new LazyImage component which would lazy load the images only when they were in the viewport, as well as store the image in the browser's local storage so that it wouldn't have to be fetched again on every visit, reducing the number of API calls to free their server as well as improve performance, reducing site memory usage down to around 400MB.
This was not the best solution. The issue was the API itself, which was not optimized for performance. The main issue was using Base64 encoded images instead of normal image URLs, as well as not using a CDN to serve the images. This time, we wanted to avoid this issue altogether.
Instead of repeating that rigid workflow and the same performance issues, we discussed a more scalable approach: using a CMS (Content Management System) such as Sanity or Contentful so EMC (Event Managers Club) and SDC (Software Development Cell) could directly manage event entries, posters, prize details, and frequent updates without developer involvement.
This decoupled content from deployments entirely and prevented us from rebuilding the site every time an event changed. We planned to formalize this pipeline after exams, once the whole team could shift back into full development mode. We also had it discussed with the college authorities, so we had full freedom.
Exams are over, Deadlines it is
Exams were over on 11th of October, and now came the real work. We had to finish the website really quickly as we had to make the website go public. The website was almost incomplete at this point. I did not know how to manage the team at such a moment, as everyone was a bit exhausted after exams, and we had a lot of work to do in a very short time. I had to make a decision.
I created GitHub issues, assigned tasks directly when no one picked them up, enforced deadlines (7 PM, extended to 7:45 at most), and made it clear that unclaimed or incomplete tasks would lead to removal from the development team. We standardized the workflow: fork → sync → develop → create PR into development → review → merge. I also instructed everyone to stick to pnpm so dependencies remained consistent and a single package manager handled everything.
We coordinated meetings, set up physical workspaces and pushed development builds to techno-new.vercel.app for quick iteration. In practice, only a few developers were available consistently, most had PATs (Periodic Assessment Tests) or scheduling clashes, so the bulk of the work (hero section, event dialogs, event list with search, responsive fixes) fell to a smaller core of contributors. It genuinely felt like running a hackathon under institutional deadlines, as Verappan bhaiya often joked.
The CMS Story
We were standing at the exact same crossroads we had stood at during Vibrance. Yes.
Prasad Sir just casually asked us a question:
"Have you started pushing events yet?"
The answer was simple: no. Nothing was approved.
During Vibrance, this exact moment had triggered chaos. Every single event update, poster change, venue correction, timing fix, everything had to go through developers. Which meant redeploys and, consequently, delays. Which meant people texting at midnight asking, “Can you just change one small thing?”
This time, we didn't want developers to be the bottleneck. We explored Sanity first and tested its API endpoints, then evaluated Contentful, which offered a smoother experience for our use-case. The core goal was to make EMC/SDC the content owners so event data could be authored and published without developer intervention. That meant building a robust pipeline so the website could reliably consume CMS data while staying performant and cost-efficient.
The goal was simple on paper:
- EMC uploads events
- Website reflects changes automatically
- No redeploys
- No developer intervention
- No midnight panic edits
Reality, of course, had other plans.
I started building the event schema. I thought about everything that could exist:
Event name, club name, event type, poster, start and end date, venue, price, participation type, maximum participants, tags, short description, long description, rules, judging criteria.
And almost immediately, I was pulled back to reality: "Why is there a max participants field?", "What should we put in tags?", "Can rules and judgment criteria be optional?"
This became a recurring theme: developers think in possibilities; organizers think in necessities.
So I started stripping things down. Removed Max participants, removed fancy tags, made rules and judgment optional, and reduced tags to just one: Special Events. What mattered most was that EMC could upload events today, not that we supported hypothetical filters six months later. That was the moment it hit me:
A schema is not about being correct. It's about being usable.
By noon, I was tweaking fields live, pushing changes, checking if they reflected on the actual website, not the playground one. At some point, I even confused the two and had to be corrected. Production was production now. There was no buffer.
Once EMC started uploading events, the events page turned into the real test of the system. Filters came first. Everything worked. The one good architectural decision we made early paid off here: only one API call. We fetched everything once and did all filtering client-side. No refetching, no CMS dependency for filters. One dataset, infinite slicing. That single choice saved us a lot of future pain.
Then came edge cases: "Why can't I see events above 1000?", "Can team size be multi-select?", "Can solo/duo/trio be combinations?"
CMS didn't support that cleanly, so we did what developers do when schemas fight back: string matching. If "SOLO" exists in the participation string, show it. Ugly? Yes. Effective? Also yes. Then UI problems surfaced, the kind you only see when real data flows in.
- Posters started resizing when descriptions opened.
- Descriptions opened by default and broke layouts.
- Paragraph breaks vanished because plain text couldn't preserve formatting.
One by one, we fixed them:
- Locked poster ratio to 4:5
- Closed descriptions by default
- Converted both short and long descriptions to Rich Text
That single Rich Text change fixed more complaints than any optimization ever could.
The Pricing, doomed; Engineering it is
Everything was going fine until we looked at Contentful's pricing.
"26k? We can't pay that."
This was Verappan bhaiya's reaction when he saw Contentful's pricing for our expected usage. We expected no expenditure. But here it is, reality hits back. Traffic hadn't even peaked yet, and requests were already piling up. At scale, we'd blow through limits frighteningly fast. Vibrance itself had crossed 15,000 hits. technoVIT would be no different.
So we redesigned the pipeline again. My first instinct was aggressive caching, one API call per user every six hours, LocalStorage, no refetching unless absolutely necessary. It would work, but it still felt fragile.
Then Verappan bhaiya suggested something that instantly felt right.
- Make one API call.
- Convert CMS data to a static JSON.
- Store it in the repo.
- Serve it from GitHub's CDN.
- Update it using a scheduled workflow.
That changed everything.
A GitHub Action now ran every hour, pulled Contentful data, regenerated a JSON file, and committed it. The website stopped talking to Contentful altogether. It just read a static file, served globally via CDN.
Sixteen days. Twenty-four hours a day.
That was 384 API calls total.
Compared to the tens of thousands we had last year, this felt unreal.
I reviewed the workflow, checked permissions, made sure secrets were in place. At one point, branch protection blocked the workflow entirely. I removed it. I made around twenty commits just to get the pipeline stable.
From “26k we can't pay” to “this should survive production” in one afternoon. This was the moment the system finally felt right. Not flashy. Not over-engineered. Just reliable.
This is not the end of the Contentful story. There is more to come. Contentful never leaves. 👀
Key Decisions
- CMS → hourly GitHub Actions → static JSON → CDN (site reads JSON)
- Client caching TTL = 6 hours (
localStorage) - Client-side filters (multi-select + two-point price slider) with
useMemoto avoid re-renders and extra API calls - Make non-critical metadata optional (rules, judging criteria) and remove hard DB constraints
- Poster aspect ratio fixed to
4:5; long descriptions stored as rich text in CMS - Temporarily relax branch protection for critical deploy windows (re-secure afterwards)
The Missing Designs: Emergency
If the CMS story was about systems failing gracefully, the design story was about designs not existing at all. At some point late in the evening, we realized something terrifying:
The mobile events page design did not exist.
The Figma file technically had it. Practically, it was an empty box. No spacing logic. No dialog behavior. No clue how filters, posters, or descriptions should behave on a phone. And the website was supposed to go live the next morning at 10 AM. There was no time for back-and-forths, no time for “waiting for design.” This was one of those moments where you stop asking for permission and start making decisions.
So we split responsibilities on the fly. Verappan bhaiya took ownership of sorting out issues, merges, and last-minute fixes. I took full responsibility for responsiveness. We designed directly in code. Poster aspect ratios broke when descriptions opened, so descriptions were closed by default. Long descriptions destroyed layouts, so we switched to rich text. Filters behaved differently on desktop, so we rethought interactions entirely for mobile.
None of this was planned. All of it was necessary. At one point, I remember staring at the site and thinking,
This feels less like web development and more like emergency architecture.
And that's exactly what it was. By the end of it, the site worked. Not perfectly. But well enough that no one outside the team would ever know how close it came to collapsing. That's the part most people never see. The quiet decisions made under pressure that kept the whole thing standing.
The Collapse Era, The Tech Drama: Teaser Video
Let my Novella narration style take over haha. You would love this!
I had just stepped out of my IEEE meeting and was walking back, ready to open my laptop and continue the usual evening work on the website, when my phone buzzed. It was a message from Katyayani. At first it felt like one of those casual "check this out" moments, until the second message came, then the third, and suddenly everything felt unusually serious. She sent me a link, our official website link, and asked why the events page had nothing. For a second I didn't understand what she meant, but when she forwarded the whole announcement, something inside me tightened. The official technoVIT website, the unreleased one that wasn't supposed to be public at all, had somehow been spread across student groups.
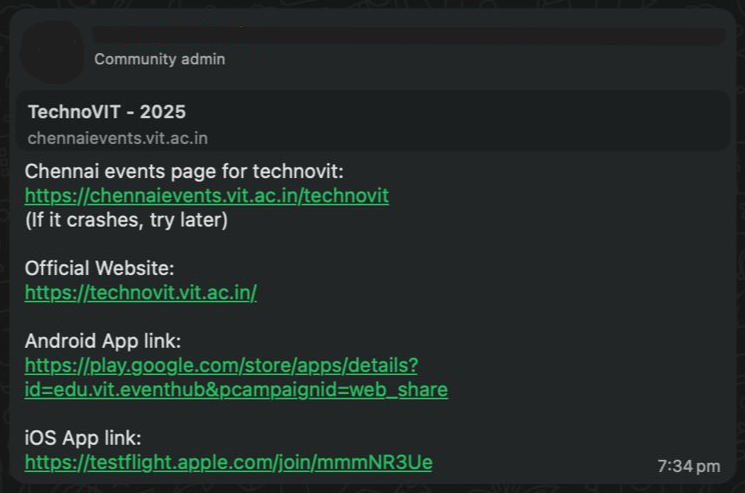
I wasn't shocked at first; I was confused. I didn't share it, the team didn't share it, no one had told us anything. I thought maybe she pulled the wrong link or maybe it was a cached version. But I opened the site, refreshed, and immediately realized the truth: it wasn't just shared, it was forwarded widely, instantly, and completely without warning. The homepage had the wrong tagline. The events page was empty. The pictures weren't loading because event posters weren't ready. Some parts of the code were even overwritten because a developer had pushed without testing. It was the exact version we never intended to show anyone.
Before I could even think of debugging, I found myself doing damage control. I texted the PR group admin asking them to delete the message. I texted another student who had forwarded it. I told them the website wasn't finalized and would not survive this kind of traffic. And while trying to explain all of this, I also had to answer the basic but painfully honest questions they asked: "Which link is the correct one?", "Why is the site slow?", "Why are the posters missing?", "Is something broken?"
It was one of those moments where you are half typing explanations, half running mental calculations, and half wondering how this happened in the first place.
In the middle of that, I opened Vercel out of instinct, expecting to see the usual stable metrics. Instead, I saw the graph that made everything inside me go blank. The bandwidth usage was almost at 75GB out of the 100GB monthly limit. For a college fest website that had been public for barely a few hours, that number was unreal. I refreshed again to make sure it wasn't a UI glitch. It wasn't. The number was rising quickly, and I knew the website would die if it reached 100GB. It wouldn't just become slow, it would shut off completely, taking every page down with it, including my personal projects on the same Vercel account.
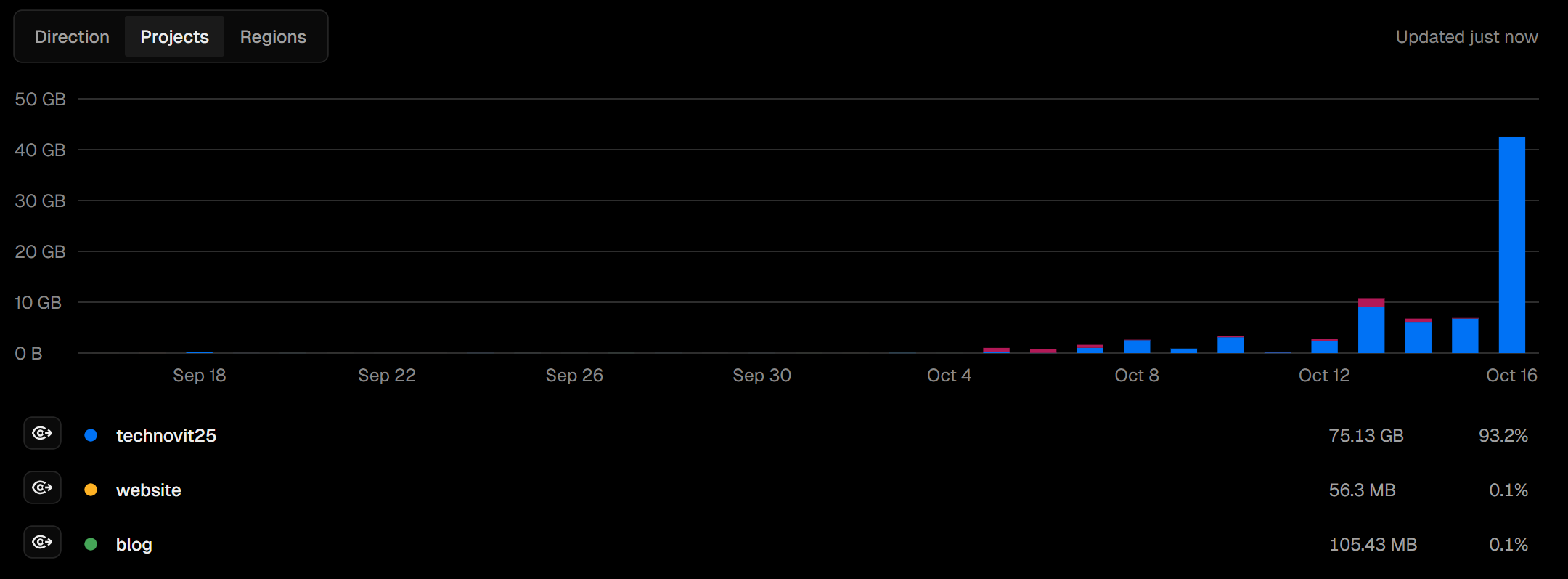
Right then, I messaged Verappan bhaiya: "the site… it will die 😭😭." He asked what happened, and I told him about the bandwidth crossing 75GB. His confusion matched mine: "How did we use 100GB?" he kept asking. The truth was, we had no idea. Nothing on the site was big enough to eat that much data in a single day. The posters weren't even uploaded properly. The events.json was tiny. The CMS wasn't serving images. None of this explained that number.

On top of that, posters had started defaulting to the technoVIT logo because the CMS wasn't returning anything. Some developer's fallback logic kicked in, so every event card showed the same logo. I didn't even have time to get annoyed about that. The CMS actions were failing because our GitHub Action was calling Contentful every 15 minutes to fetch updated events. But that still didn't explain the bandwidth explosion. Everything felt wrong at the same time.
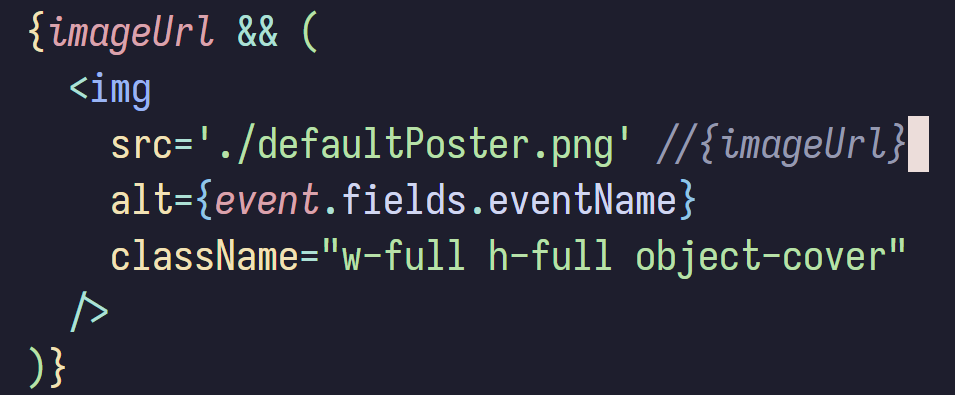
The events page wasn't the only issue. The homepage tagline had been mysteriously changed by another developer, overwriting earlier work. The team page images weren't showing up because someone pushed outdated code. Everything I had tested carefully before seemed to fall apart within minutes. And there I was, switching between WhatsApp chats, Vercel analytics, GitHub commits, and broken UI, trying to put together where things had gone off the rails.
Then I did the one thing I should have done first: I opened Vercel Analytics and checked the route usage. And there it was, sitting at the top like a villain waiting to be exposed. A single file had eaten almost 40GB of bandwidth by itself.
/trailer.mp4
A 60MB teaser video that auto-played on the homepage. Every new visitor downloaded the entire file on page load. Multiply that by just a thousand users and you get the numbers we were seeing. It explained everything instantly. And it was so obvious only in hindsight. I remember messaging bhaiya: "it was the trailer all along." His response was almost a comedic breakdown: "BRO WHAT WAS I THINKING PUTTING A 61MB FILE IN PUBLIC FOLDER 🥲🫠😂." He wasn't wrong. If both of us had slept for an hour longer that day, the entire website would have run out of bandwidth and gone offline before midnight.
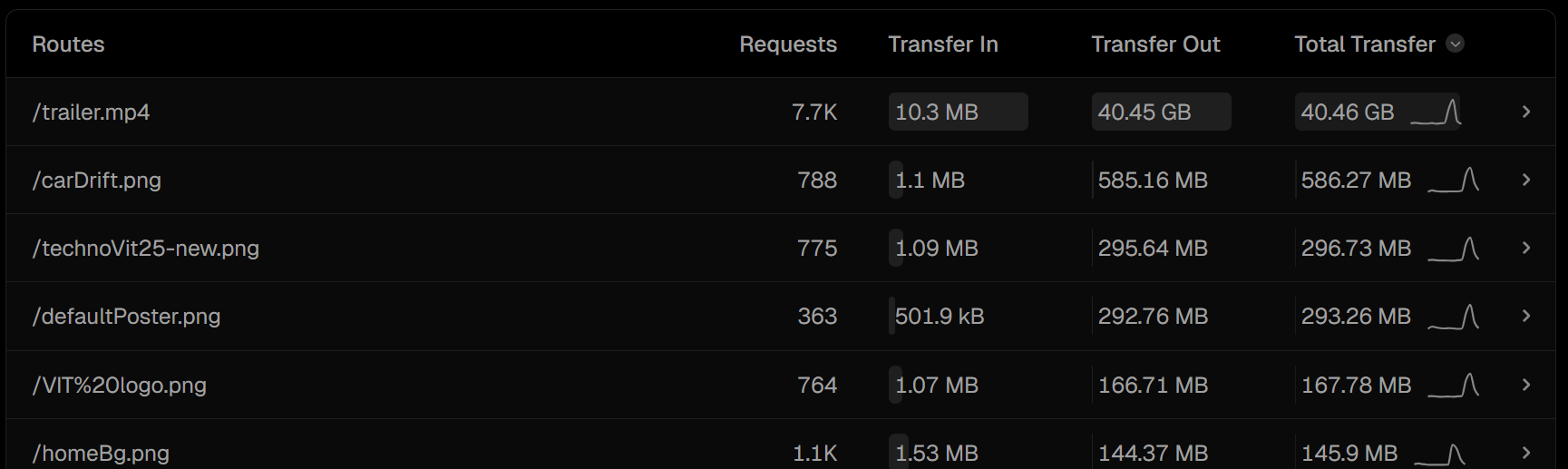
Once we removed the trailer, the bandwidth stopped rising so aggressively, but the situation wasn't solved. We had around 20GB left, and we needed the website to survive until morning at the very least. So we made a decision instantly: move all data, images, events, posters, off Vercel and onto a separate CDN. I already had a Cloudflare bucket ready, so I rewired the GitHub Action to generate events.json inside cdn.a2ys.dev, pushed the posters there, and changed the image URLs across the site.
The goal was very simple: Vercel should only serve the website shell, nothing else. Every heavy asset had to load from Cloudflare's 1TB bandwidth instead. I changed the code, optimized images, removed unnecessary large objects, and updated fetch logic. When the CDN finally responded correctly, I remember typing to bhaiya: "the website… it's saved."
But that wasn't the end. Posters still needed formatting because someone had changed the ratio logic. The default logos kept appearing because fallback conditions were misconfigured. The mobile navbar logo had reverted to an old version. Even while fixing the CDN issue, we were still discovering new layers of problems caused by rushed pushes from the team. I was patching UI issues, debugging responsive layouts, checking GitHub PRs, and answering messages from people who thought they broke something by visiting the site.
Only after midnight did everything slowly become stable. The CDN responded instantly, posters loaded again, events.json refreshed correctly every fifteen minutes, and the bandwidth graph finally froze instead of climbing. And for the first time in three hours, I could breathe normally. I remember asking my roommate to check the site and confirm everything worked. When he said yes, I finally closed my laptop, leaned back, and let out a long sigh.
Looking back, the dramatic part wasn't the trailer or the bandwidth or the debugging itself. It was the chain reaction that started from one unexpected message, the shock of realizing the site was public before we were ready, the miscommunications, the overwritten code, the CMS issues, the rising bandwidth graph, and the sudden responsibility of preventing a full shutdown while everyone around me assumed everything was fine. That night felt like handling a production outage disguised as a college fest website, and somehow, through a mix of panic, engineering, and pure adrenaline, we managed to pull it back.

The trailer was just a file. The collapse was everything around it.
That night stays with me because it showed how suddenly systems can fall apart, and how fast you have to think when hundreds of people are unknowingly stressing something you built. And most of all, how one small detail, a 60MB video sitting quietly in the public folder, can push an entire website to the edge without anyone realizing it until the last possible moment.
The Diwali Outage: AWS, the Unexpected Guest and More Drama
The AWS outage unfolded almost like a slow-moving plot twist, and the funniest part is that it began on Diwali afternoon, the one day when nobody expects anything stressful to happen. I wasn't coding, I wasn't debugging, in fact, I wasn't even thinking about the website. Everything was peaceful until 2:17 PM, when I suddenly got a message: "Hey bro…site down again????"
At first, I genuinely thought he was mistaken. At 2:17 PM I replied, "no, why?" At 2:18 PM, he sent a screenshot showing the events page failing. By 2:19 PM, he apologized for disturbing me on a holiday, which only convinced me more that he wasn't trolling.
I opened my laptop thinking I'd just check one request and close it. But the moment the site loaded, the entire UI felt wrong. The events weren't appearing, internal server errors appeared in the network tab, and the version of the website being shown looked like a day-old cached build. At 2:22 PM, I messaged him: "wait how." By 2:23 PM, I was refreshing deployments and realizing none of them were updating. Vercel itself wasn't responding. Logs wouldn't load. Preview builds didn't trigger.

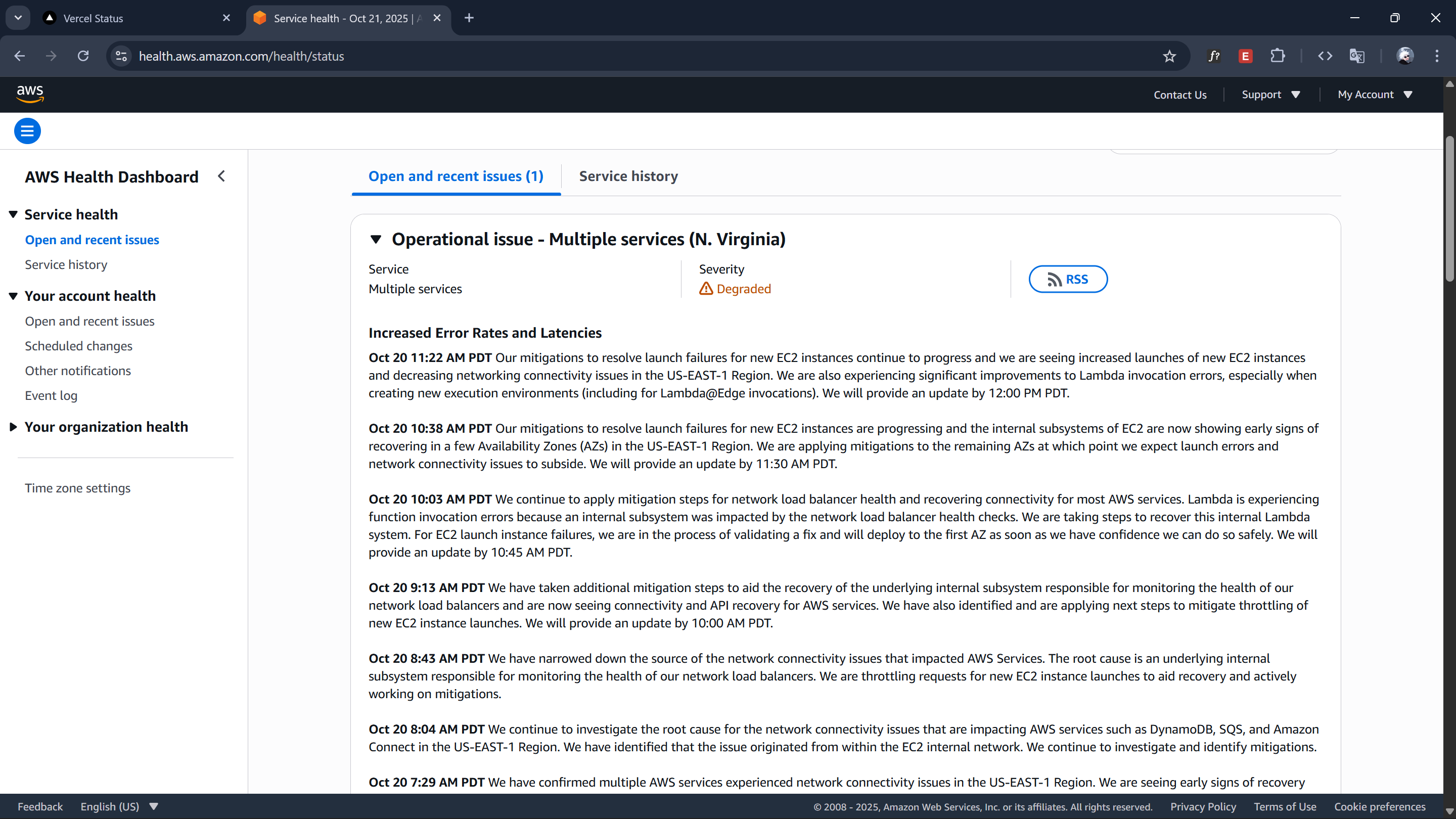
At 2:27 PM, I finally said it: "there is a Vercel outage." And that alone didn't make sense, so I dug deeper. By 3:06 PM, reality hit: "aws is down, in short, entire world internet."
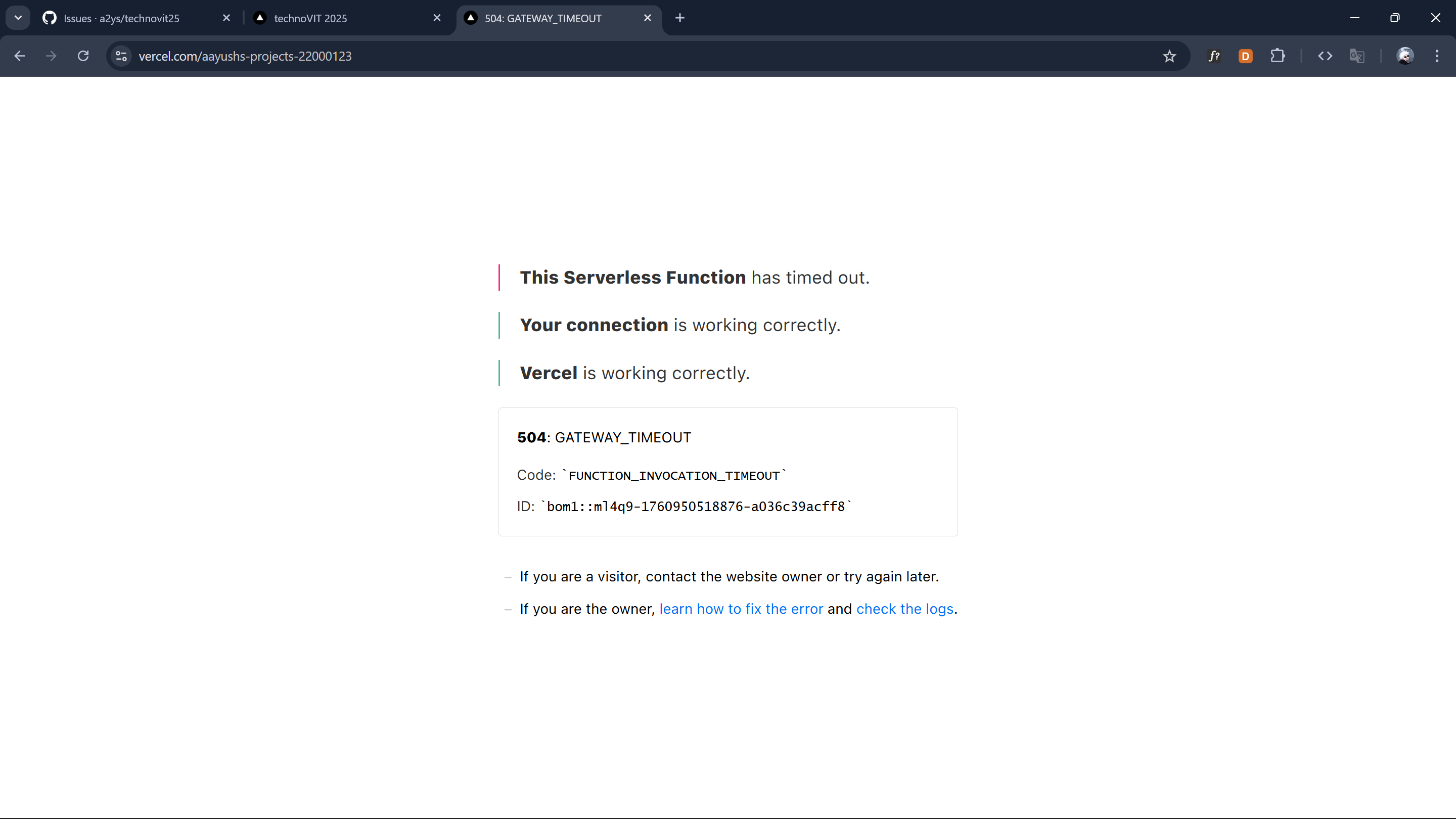
I wasn't exaggerating. It was a historic collapse. EC2, S3, DynamoDB, CloudFront, Lambda, all marked red. Dozens of core systems were failing simultaneously. Even Vercel's build systems were stuck because their infrastructure depends on AWS. This was the first time I ever saw Vercel completely lose control of their own platform.
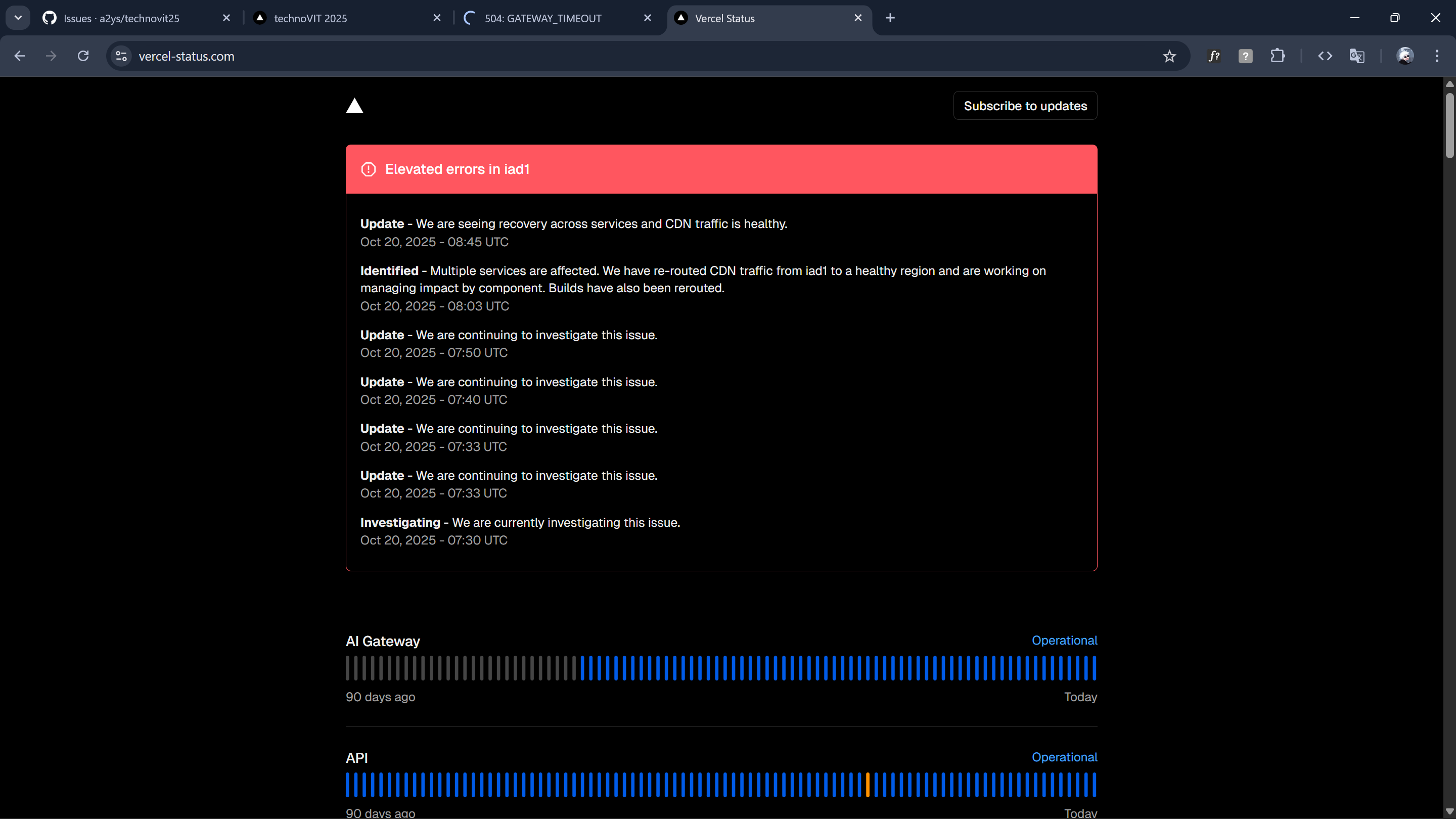
People kept messaging me from everywhere. Apps weren't loading, tools weren't working, websites were freezing. From 2:55 PM to 3:01 PM, I listed everything falling apart: Snapchat, Canva, Crunchyroll, Duolingo, Coinbase, Perplexity, NY Times, Apple TV, Wordle, PUBG, Amazon, Roblox, Fortnite, Goodreads, Ring, Xero, Playstation, Pokémon Go, Life360 and the list kept increasing. Even hospitals and clinics were affected because their backend systems ran through AWS.

I checked AWS's official status page and saw an endless wall of failures, more than 100 services red at the same time. At 2:59 PM, I sent a screenshot to another friend: "aws hi down 👆🏻 pura dunia ka internet down." By 3:03 PM, I confirmed: "DynamoDB aur EC2 ka game over."

This screenshot I took was old, and the degraded services were just growing, and the impacted services list kept expanding. And it genuinely was. The outage kept growing. By midnight, I sent another message: "history me itna der aws nahi band hua hai."
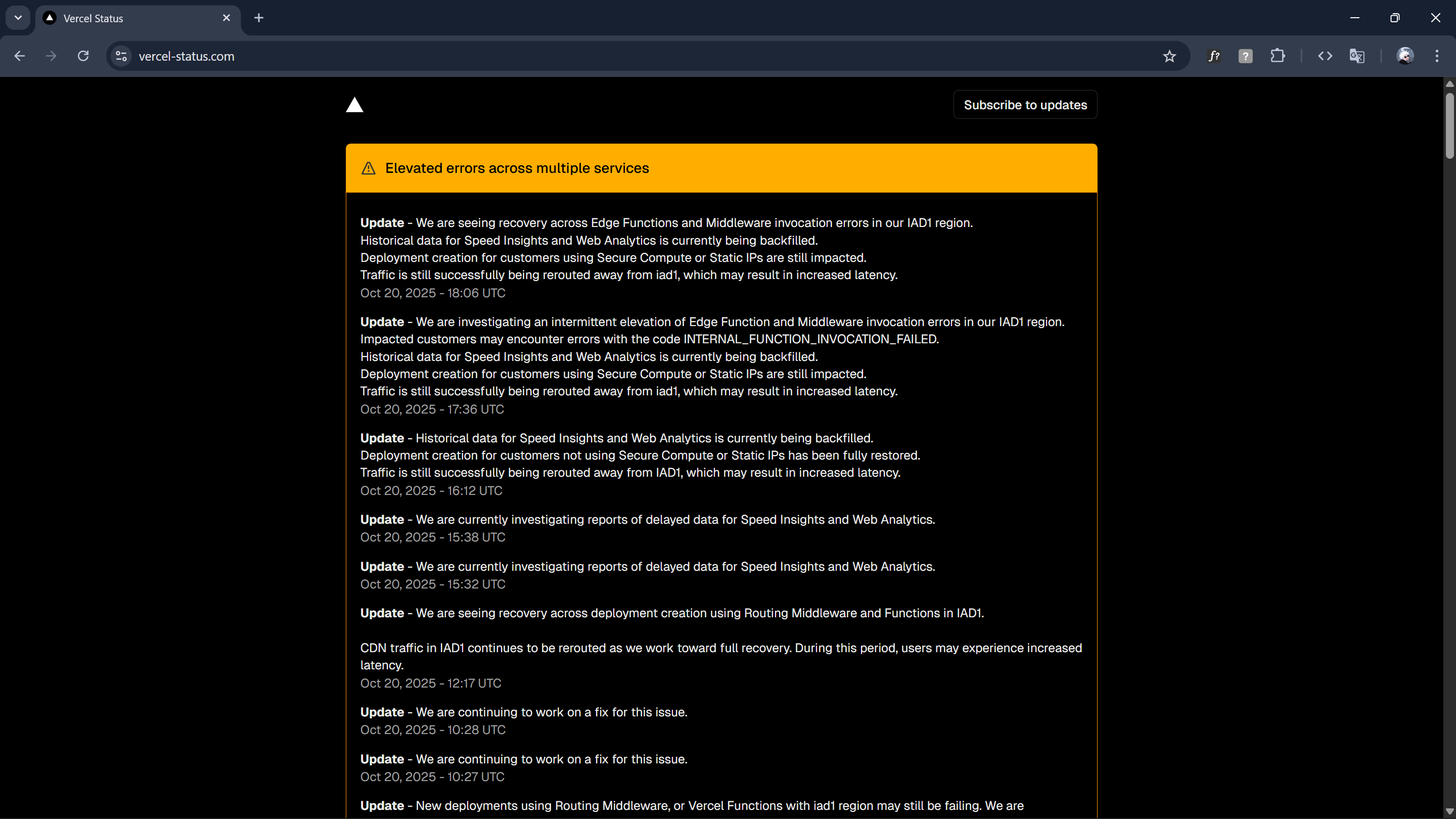
Vercel wasn't doing any better. When I opened their status page, everything was broken.
- Deployments: down.
- Logs: down.
- Analytics: down.
- Routing: down.
- Speed Insights: down.
- Edge functions: down.
- v0: down.
Even their own website barely loaded. I messaged: "Vercel ka to game hi over chal rha hai." At this point, I wasn't debugging technoVIT, I was witnessing the entire modern internet collapse layer by layer.
Meanwhile, I was still getting website messages. The funniest and saddest part: people still thought it was a technoVIT website bug. At 2:27 PM, I reassured the first guy: "site is constantly being developed… thanks for pointing out!" At 3:26 PM, he said it was working again. I had to explain: "aws is still down, these are not the latest changes."
At 10:09 AM next morning, once AWS began recovering, Verappan bhaiya messaged: "Bhaijan check now." By 10:17 AM, I deployed the changes I had been trying to push for over a day.
While AWS was down, I was ironically doing some of the biggest performance improvements on the entire website, ,optimizing components, removing heavy calculations, adding caching, improving FPS on the events page using Intersection Observer, memoizing everything, refactoring dozens of files. The entire site became faster but none of it could be deployed.
By October 21st evening, AWS recovered, Vercel recovered, Deployments worked and all improvements finally went live. But the most interesting part of this whole absurd day wasn't even the debugging. It was watching the entire internet, all at once, crumble because one company had a bad afternoon.
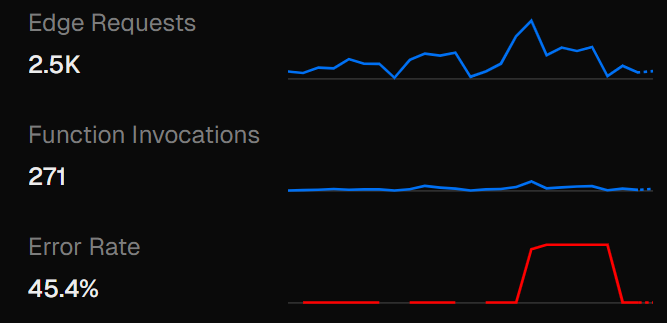
For the first time in my life, I didn't read about a global outage as a spectator, I lived inside it, responsible for something running on it, watching request after request fail for reasons completely outside my control. This was the craziest thing that happened during the technoVIT website journey, but there was still more chaos waiting ahead.